AI가 글을 읽고 이미지를 그리게 만든 방법 — Gemini 블로그 이미지 파이프라인
블로그 글 내용을 분석해서 장면별 이미지를 자동 생성하는 시스템. 참고 사진 분위기 반영, 히어로 이미지 전략, 모델 fallback까지.

“이미지 4장 만들어줘”는 자동화가 아니다
블로그에 이미지를 넣을 때 보통 이렇게 한다. 글을 쓰고, 글의 분위기에 맞는 이미지를 머릿속으로 구상하고, 프롬프트를 직접 써서 AI에 요청한다. 4장이면 4번, 8장이면 8번.
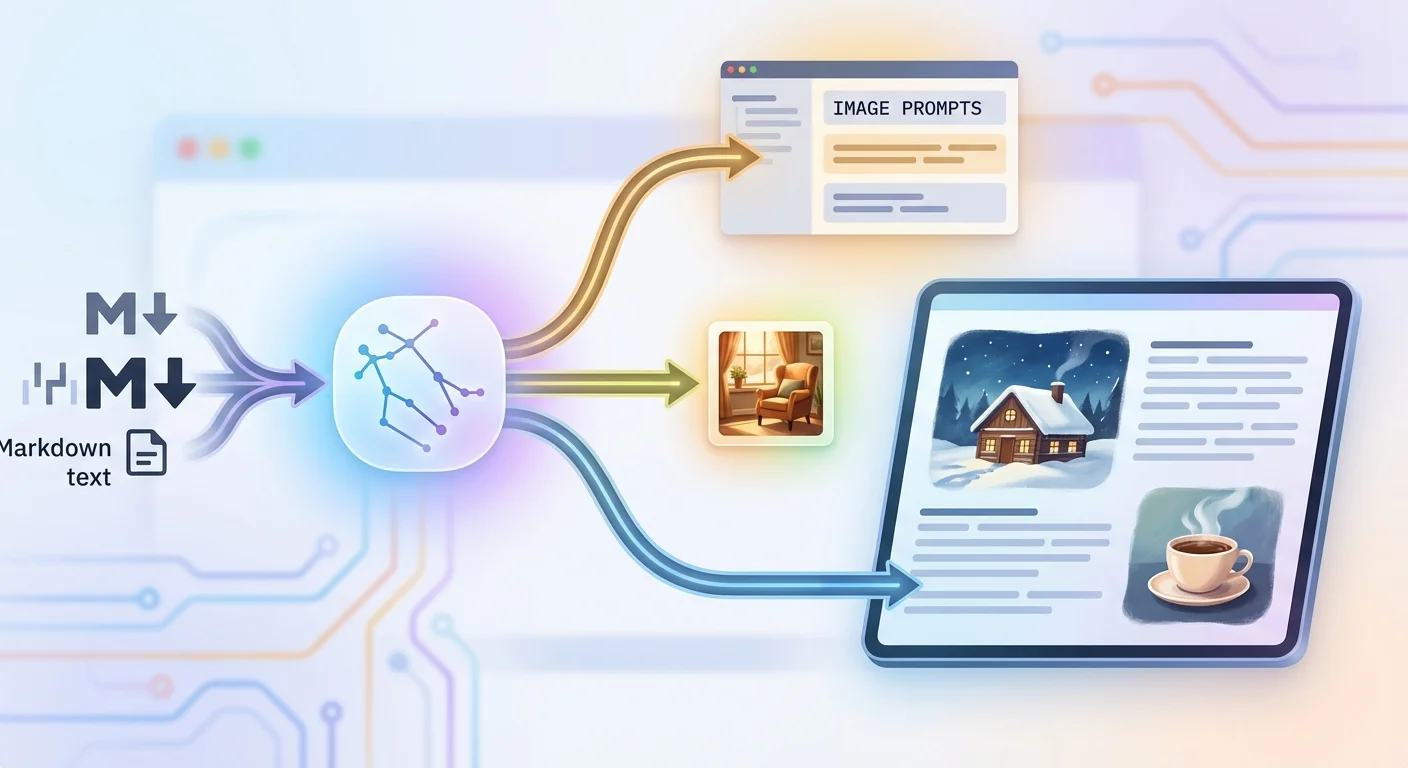
나는 이게 귀찮았다. 글을 쓰면 이미지가 알아서 나와야 하지 않나? 글 내용을 읽고, 어떤 장면이 필요한지 파악하고, 분위기에 맞는 프롬프트를 생성해서 이미지를 만들어주는 시스템. 그걸 만들었다.
결론부터 말하면, 지금 내 텔레그램 봇은 이렇게 동작한다.
- 글 본문을 Gemini가 분석한다
- 장면별 이미지 프롬프트를 자동 생성한다
- 참고 사진이 있으면 분위기를 반영한다
- 히어로 이미지를 마지막에 만든다
- 모델이 실패하면 자동으로 다음 모델로 넘어간다
이 글에서는 각 단계의 기술적 구조와 “왜 그렇게 만들었는지”를 설명한다.

1단계: 글 본문 분석 → 프롬프트 자동 생성
핵심은 analyze_post_for_images() 함수다. 블로그 포스트의 마크다운 본문을 Gemini 2.5 Flash에게 보내면, 장면별 이미지 프롬프트를 반환한다.
1
2
3
4
5
6
7
8
9
10
11
12
analysis_prompt = (
f"You are generating image prompts for a Korean blog post.\n"
f"Topic: {topic}\n"
f"Post content:\n{post_content[:3000]}\n\n"
f"Generate exactly {count} image prompts.\n"
f"Rules:\n"
f"1. Prompt #1 is the HERO image (wide 16:9 landscape).\n"
f"2. Prompts #2-N: specific scenes from different sections.\n"
f"3. Each prompt MUST describe a concrete, specific scene.\n"
f"4. Match the mood: winter → cool tones, cafe → warm tones.\n"
f"5. Style: stylized digital illustration, NOT cartoonish.\n"
)
여기서 중요한 건 “구체적인 장면을 그려라”는 규칙이다. “데이팅에 대한 추상적 이미지”가 아니라 “겨울 밤 편의점 앞에서 아메리카노를 들고 서 있는 사람”처럼, 글에서 실제로 묘사하는 장면을 그리게 한다.
처음에는 주제(topic)만 던져주고 이미지를 만들었는데, 글과 이미지가 따로 놀았다. 글에서 카페 이야기를 하는데 이미지는 산속 풍경이 나오는 식이다. 본문 전체를 분석하게 바꾸니까 정합성이 확 올라갔다.
이미지 개수도 글이 결정한다
이미지를 무조건 4장 만드는 것도 비효율적이다. 짧은 글에 8장은 과하고, 긴 글에 3장은 부족하다.
1
2
3
4
def _calc_image_count(post_content: str) -> int:
sections = post_content.count('\n## ') + post_content.count('\n---')
count = max(4, min(8, sections // 2 + 1))
return count
섹션 수를 세서 이미지 개수를 동적으로 결정한다. ## 헤딩이나 --- 구분선이 많으면 그만큼 장면이 많다는 뜻이니까. 최소 4장, 최대 8장.
2단계: 참고 사진의 분위기를 반영하다
최근 추가한 기능이다. 글에 대한 참고 사진이 있으면(예: 카페에서 찍은 실제 사진), 그 사진의 분위기를 이미지 생성에 반영한다.
구현 구조는 2단계로 나뉜다.
Step 1: 참고 사진을 Gemini에게 보내서 분석한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
async def _analyze_reference_images(ref_image_paths):
analyze_prompt = (
"Analyze these reference photos and describe:\n"
"1. Location/setting\n"
"2. Atmosphere/mood\n"
"3. Color palette\n"
"4. Key visual elements\n"
"5. Time of day and season indicators\n"
)
# 이미지를 Gemini에게 전달
contents = image_parts + [analyze_prompt]
response = client.models.generate_content(
model="gemini-2.5-flash", contents=contents
)
return response.text # "따뜻한 조명의 카페, 원목 테이블..."
Step 2: 분석 결과를 프롬프트 생성에 주입한다.
1
2
3
4
5
6
📷 REFERENCE PHOTOS CONTEXT:
Warm-lit café interior with wooden tables, ambient
lighting, and minimalist decor. Cozy evening atmosphere.
IMPORTANT: Use the atmosphere, setting, colors from
these reference photos in your image prompts.
이렇게 하면 “따뜻한 카페 분위기”가 모든 이미지 프롬프트에 녹아든다. 실제 카페 사진을 올리면, 그 카페의 분위기가 일러스트에 반영되는 거다.
왜 이미지를 직접 이미지 생성 모델에 넣지 않고 텍스트 분석을 거치냐면, Imagen 4 (Fast/Ultra)는 텍스트-to-이미지 모델이라 참고 이미지를 입력으로 받지 못한다. 그래서 참고 이미지 → 텍스트 분석 → 프롬프트 반영 경로를 택했다.

3단계: 히어로 이미지를 마지막에 만드는 이유
블로그의 히어로 이미지(대표 이미지)는 가장 중요하다. 검색 결과, SNS 공유, RSS 피드에서 가장 먼저 보이는 이미지다. 그런데 이걸 가장 먼저 만들면 문제가 생긴다.
이유는 단순하다. 본문 이미지를 먼저 만들면 글 전체의 시각적 맥락이 형성된다. 히어로 이미지는 그 맥락을 종합해서 만들어야 가장 잘 나온다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 1) 본문 이미지 먼저 (인덱스 1~N)
for i in range(1, len(prompts)):
results[i] = await generate_image(
prompt=prompts[i], filename=f"{slug}-{i+1}.webp"
)
# 2) 히어로 이미지 마지막 (인덱스 0)
hero_prompt = (
f"{prompts[0]}\n\n"
f"IMPORTANT: This is a HERO image. "
f"Must be wide 16:9 landscape aspect ratio."
)
results[0] = await generate_image(
prompt=hero_prompt, filename=f"{slug}-1.webp"
)
실제 A/B 테스트는 안 했지만, 체감상 히어로를 나중에 만들면 글의 첫 장면을 더 정확하게 묘사한다. Gemini가 프롬프트 분석 단계에서 전체 글을 이미 읽었기 때문에, 순서가 바뀌어도 프롬프트 자체는 같다. 다만 API 호출 간의 미묘한 컨텍스트 차이가 있을 수 있다.
히어로 이미지에 추가하는 조건이 하나 더 있다. 16:9 가로형 비율 강제. 세로형 히어로는 블로그 레이아웃을 깨뜨린다.
4단계: 모델 Fallback — 실패는 당연한 것
AI 이미지 생성 API는 생각보다 자주 실패한다. 쿼터 초과, 컨텐츠 필터링, 서버 에러, 타임아웃. 한 모델에만 의존하면 “이미지 생성 실패” 메시지를 너무 자주 보게 된다.
내 시스템의 모델 우선순위 체인은 이렇다.
Fast 모드 (기본값, $0.02/장)
1
Imagen 4 Fast → Gemini 2.5 Flash → Gemini 3 Pro → Placeholder
Pro 모드 (고품질, $0.134/장)
1
Gemini 3 Pro → Gemini 2.5 Flash → Imagen 4 Fast → Placeholder
각 모델마다 Vertex AI 클라이언트와 AI Studio 클라이언트를 모두 시도한다. 한쪽의 쿼터가 차면 다른 쪽에서 처리한다.
1
2
3
4
5
6
for model in model_chain:
for client, client_name in clients:
image_data = await _try_generate(client, model, prompt)
if image_data:
return image_data # 성공 즉시 반환
# 이 모델 전체 실패 → 다음 모델로
최악의 경우 모든 모델이 실패하면 SVG 플레이스홀더를 생성한다. 이미지가 없어서 포스팅 자체가 안 되는 상황은 피해야 하니까.
Fallback 프롬프트도 필요하다
Gemini 분석이 실패할 수도 있다. 이때를 위한 fallback 프롬프트 시스템도 만들었다. 8개의 템플릿을 준비해두고, 요청 수만큼 순서대로 할당한다.
1
2
3
4
5
6
7
templates = [
"Wide panoramic illustration for: {topic}...",
"Scene illustration about: {topic}...",
"Detail scene for: {topic}...",
"Result/outcome scene for: {topic}...",
# ... 8개까지
]
처음에는 4개만 만들어놨다가, 8장짜리 포스트에서 뒤의 4장이 생성되지 않는 버그가 발생했다. 장면이 많아질수록 fallback도 다양해야 한다.
중복 방지 — 히어로 이미지가 본문에 또 나오는 문제
이미지 파이프라인을 만들고 나서 발견한 버그가 있다. Claude가 글을 쓸 때, frontmatter의 히어로 이미지(slug-1.webp)를 본문에도 넣어버리는 경우가 있었다. Jekyll Chirpy 테마는 frontmatter의 image:를 히어로로 자동 렌더링하기 때문에, 본문에 같은 이미지가 또 나오면 중복이 된다.
해결은 프롬프트 규칙 추가 한 줄이었다.
1
2
⚠️ 히어로 이미지(slug-1.webp)는 frontmatter image에만 사용.
본문(body)에는 절대 넣지 마. 본문 이미지는 -2부터 시작.
AI 기반 자동화의 특성상, 규칙을 명시하지 않으면 AI가 “합리적인 판단”으로 중복을 만든다. 사람이라면 당연히 안 할 실수를 AI는 자연스럽게 한다. 이런 엣지 케이스를 발견할 때마다 규칙을 추가하는 게 이 시스템의 유지보수 방식이다.

그래서 지금 어떻게 동작하나
텔레그램에서 “블로그 써줘”를 보내면:
- Claude가 글을 먼저 쓴다 (5분 내)
- 글 본문을 Gemini가 분석 → 장면별 프롬프트 4~8개 생성
- 참고 사진이 있으면 분위기 분석 → 프롬프트에 반영
- 본문 이미지 먼저 생성 → 히어로 이미지 마지막
- 실패한 모델은 자동으로 다음 모델로 교체
- 이미지를 블로그 폴더에 저장 + 구글드라이브 백업
- git push → 배포
이 모든 게 한 번의 메시지로 끝난다.
비용은 Fast 모드 기준 이미지 4장에 약 $0.08, 6장에 $0.12다. 한 달 30개 포스트를 써도 이미지 비용은 $3.6 이하.
이미지 품질이 아쉬우면 “프로 품질로 재생성”을 누르면 된다. 그때만 Gemini 3 Pro가 동작해서 장당 $0.134를 쓴다. 기본값을 저렴하게 유지하면서, 필요할 때만 품질을 올리는 구조다.
자동화의 핵심은 “기본 동작은 저렴하고 빠르게, 예외 상황은 확실하게 처리”라고 생각한다. 이미지 파이프라인도 그 원칙을 따른다.